DMTet论文精读
一个用于高分辨率三维形状合成的混合表示方法 | NeurIPS 2021
概述
DMTet是Deep Marching Tetrahedra的简称,其中Tentrahedron是四面体的意思。而这个技术的核心在于,使用者仅需提供简略的输入(体素/点云),就能转成高清的3D Mesh。
DMTet的架构
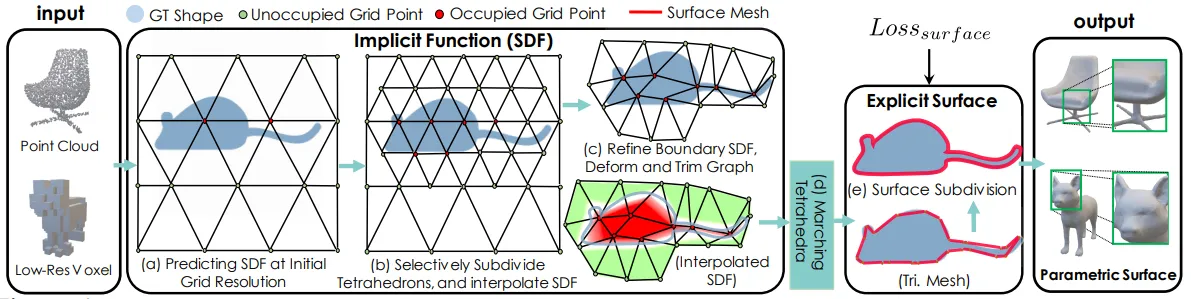
由左向右看,DMTet利用定义在可变形的四面体网格中的SDF来隐式表示3D物体表面。可变形四面体网格的好处在于,能够较有效率的去表示物体的几何形状。更仔细看可以发现,SDF的值是被定义在四面体的顶点中,剩余空间的SDF则是透过对这些顶点的线性内插取得。
初始化
为输入的点云/体素初始化一个粗糙的四面体网格,然后使用神经网络预测每个顶点的SDF值。
首先,使用PVCNN作为输入编码器提取特征向量Fvol(v,x),之后使用多层感知机(MLP)来预测顶点的SDF值:
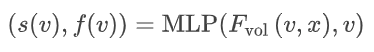
体积细分
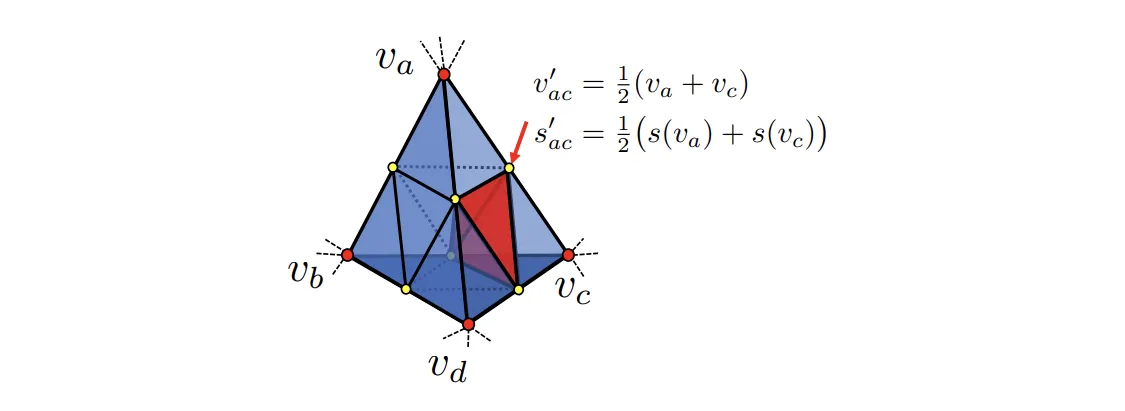
DMTet在学习的过程中若判断四面体有包含到物体表面,则此时会再将该四面体切成八小块,如下图所示,目的是增加四面体网格的分辨率,特别是在预测表面附近,以更好地捕捉形状的细节。
体积细分结束后,DMTet会对四面体网格进行表面细化,将不包含在边界四面体内的顶点剔除掉,以节省存储资源。
最右边输出的部分,DMTet也有针对进行表面细化,并将这些切割参数(例如切割出来的Vertices位置) 也视为整体Deep Learning的一部分。
生成器与判别器
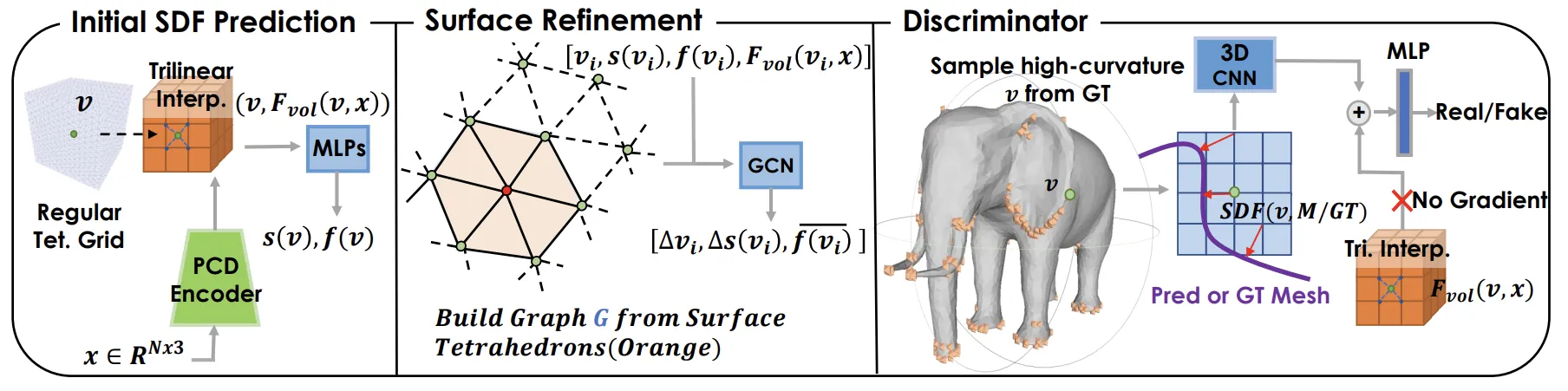
由左向右看,Generator的Input若是Point Cloud Data (PCD),则会以PVCNN作为Encoder; 而Input若是Voxel Data,则是对表面进行采样。接着会将前述步骤得出的特征向量带入MLP进行SDF的预测。得出初始SDF值后,会开始反覆地对物体表面预测进行优化,也就是表面细化这个步骤。
生成器(Generator)的作用是接收一个潜在向量(通常是随机噪声)作为输入,并生成与训练数据相似的样本。生成器的目标是生成逼真的样本,以至于判别器无法准确区分生成的样本和真实样本。生成器可以看作是一个生成模型,通过学习训练数据的分布特征,生成与之相似的新样本。
判别器(Discriminator)的作用是接收样本(可以是真实样本或由生成器生成的样本)作为输入,并预测样本的真实性。判别器的目标是对样本进行分类,判断样本是真实的还是生成的。判别器可以看作是一个判别模型,它学习如何区分真实样本和生成样本,并提供对生成样本的反馈信号给生成器。
生成器和判别器通过对抗训练的方式相互竞争和协作。生成器的目标是欺骗判别器,使生成的样本越来越接近真实样本,以至于判别器无法准确区分。判别器的目标是尽可能准确地分类样本,使得真实样本和生成样本之间的差异更加明显。通过迭代的对抗训练过程,生成器和判别器不断调整自己的参数,以达到一个平衡点,最终生成器能够生成逼真的样本,而判别器无法准确区分真实和生成样本。
表面细化
首先第一步是基于SDF的值去找出物体表面的边界四面体。如上图橘色区所示,DMTet会基于红点SDF (在物体表面内)去建出构建图G =(Vsurf,Esurf),其中Vsurf,Esurf对应于Tsurf中的顶点和边,并通过GCN去预测橘区内剩余顶点的位置的Offset ∆vi以及SDF值的预测误差∆s(vi )。
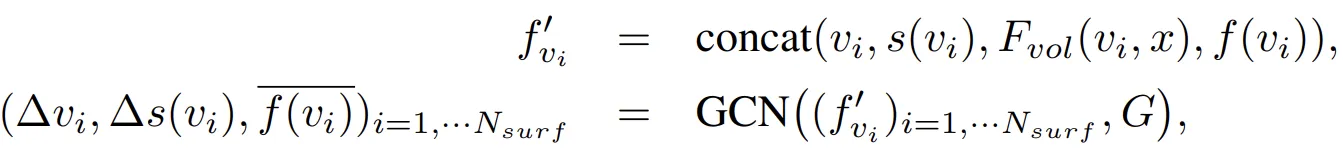
上式中Nsurf是边界四面体中的顶点数量,f'vi是将vi, s(vi), Fvol(vi, x)以及f(vi)衔接起来的向量。而更新vi的方式如下:
v 'i = vi + ∆vi s(v 'i ) = s(vi) + ∆s(vi)
表面细化有助于改善局部几何结构,通过调整顶点位置和SDF值来优化形状的表面细节。
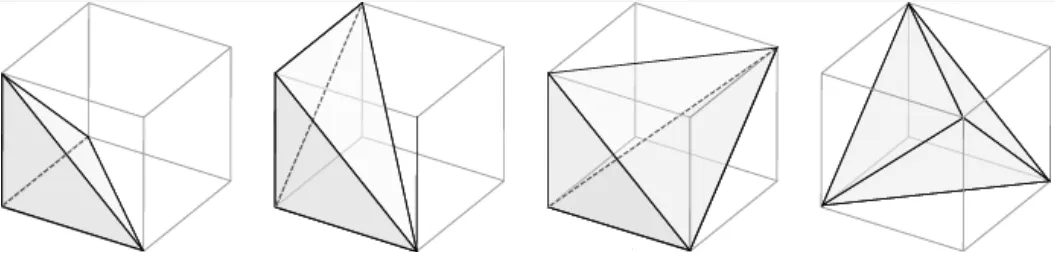
Marching Tetrahedra
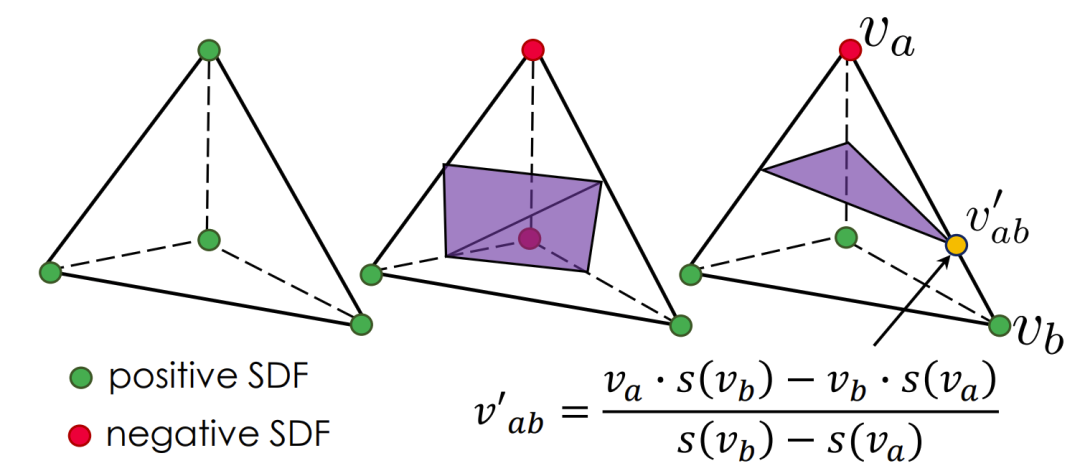
MT基于s(v)的符号确定四面体内部的表面类型,如上图所示。构型总数为24 = 16,考虑旋转对称性后,分为3种独特的情况。一旦四面体内部的表面类型被识别,等值面的顶点位置在沿着四面体的边缘的线性插值沿着的零交叉处被计算。
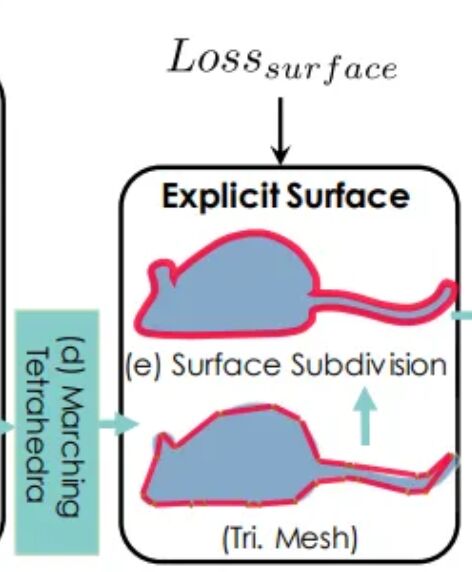
而生成器的最后一个步骤,则是将通过MT取出的网格,也通过GCN进行表面细分,预测顶点位置,如下图所示:
3D 判别器
DMTet用3D CNN DECOR-GAN作为Discriminator的架构,将基于Ground Truth Meshes所算出的SDF与生成器预测的顶点所算出的SDF作为Input,来学习分辨网格上的顶点是来自生成器所预测的还是来自Ground Truth Meshes。
首先从目标网格中随机选择一个高曲率顶点v,并计算v周围体素化区域的地面真值有符号距离场Sreal 。同样,我们计算同一位置的预测表面网格M的有符号距离场,得到Spred 。将Sreal或Spred与位置v中的特征向量Fvol(v,x)一起沿着判别器中。判别器预测指示输入是来自真实的还是生成的形状的概率。
损失函数

表面对齐损失Lcd

- Pgt 是从真实形状的表面采样的一组点。
- Ppred 是从生成形状的表面采样的一组点。
- 这个损失函数衡量两组点之间的距离,包括从预测点到最近真实点的距离,以及从真实点到最近预测点的距离。这有助于确保生成的形状在表面上与真实形状紧密对齐。
法线一致性损失 Lnormal
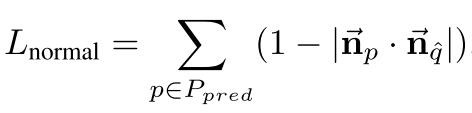
- np是预测点 p的法线向量。
- nq是真实点 q的法线向量,q 是对应于 p的真实值最近点。
- 这个损失函数衡量预测点和其对应真实点的法线向量之间的一致性。它鼓励生成的形状不仅在位置上与真实形状匹配,而且在表面方向上也保持一致。
符号距离函数损失 LSDF
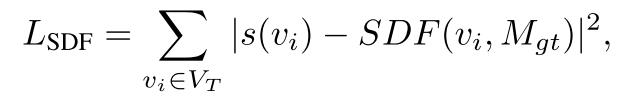
-
VT 是四面体网格中所有顶点的集合。
-
s(vi) 是顶点 vi处的符号距离函数值,表示该点到最近表面的最短距离。
- SDF(vi,Mgt) 是顶点 vi相对于真实(Ground Truth)形状 Mgt 的符号距离函数值。
- 这个损失函数衡量生成器预测的SDF值与真实形状的SDF值之间的差异。通过最小化这个损失,生成器学习生成的SDF值更接近真实形状,从而提高生成形状的准确性。
顶点变形正则化损失 Ldef
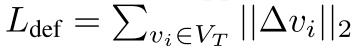
- Δvi 是顶点 vi 的位置变化量,表示在优化过程中顶点位置的调整。
- 这个损失函数对顶点位置的变化量进行正则化,以避免过大的变形,这有助于保持生成形状的稳定性和减少生成过程中可能出现的伪影或失真。
生成器的对抗损失 LG
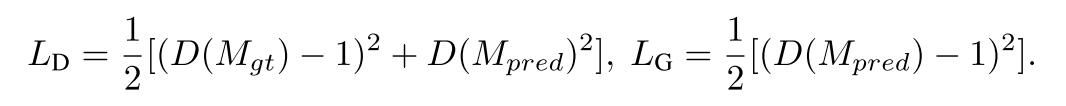
- 生成器的目标是最小化判别器将其生成的数据识别为真实数据的能力。因此,生成器的对抗损失函数鼓励判别器将生成数据的预测值接近1,即生成器的目标是“欺骗”判别器,使其认为生成的数据是真实的。
判别器的损失 LD
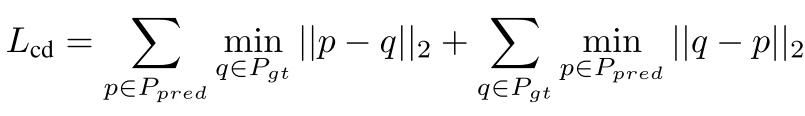
-
D(Mgt) 是判别器对真实数据 MgtMgt 的预测。
-
D(Mpred)D(Mpred) 是判别器对生成数据 MpredMpred 的预测。
-
判别器的目标是最大化其区分真实数据和生成数据的能力。因此,判别器的损失函数包括两部分:
-
D(Mgt)−1)^2:这部分鼓励判别器将真实数据的预测值接近1。
- D(Mpred)^2:这部分鼓励判别器将生成数据的预测值接近0。
DMT的更新过程
在DMTET(Deep Marching Tetrahedra)模型中,更新过程涉及到生成器和判别器的交替训练,这是典型的生成对抗网络(GAN)的训练方式。以下是DMTET模型更新的基本步骤:
-
初始化网络参数:
- 生成器和判别器的网络参数被初始化,通常是随机初始化。
-
训练循环:
- 进入一个迭代的训练循环,通常包括以下步骤:
-
生成器的前向传播:
- 使用当前的生成器参数,从输入数据(如粗糙体素或点云)生成3D形状。
- 通过可微分的Marching Tetrahedra层将隐式的SDF表示转换为显式的三角网格。
-
判别器的前向传播:
- 使用判别器评估真实形状和生成形状。
- 判别器尝试区分真实形状和生成形状,输出一个概率值。
-
计算判别器的损失 LD:
- 使用判别器的损失函数来计算判别器的损失,该损失反映了判别器区分真实和生成数据的能力。
-
更新判别器:
- 根据 LDLD 的梯度更新判别器的参数,目的是提高判别器的区分能力。
-
计算生成器的损失 L:
- 使用生成器的损失函数来计算总损失,包括表面对齐损失、法线一致性损失、对抗损失、SDF损失和顶点变形正则化损失。
-
更新生成器:
- 根据 LL 的梯度更新生成器的参数,目的是提高生成形状的质量,并欺骗判别器。
-
重复训练循环:
- 重复步骤3-8,直到满足停止条件,如达到预定的迭代次数或性能指标。
-
模型评估:
- 在训练过程中,定期评估模型的性能,可能包括在验证集上的评估和可视化生成的3D形状。
可能的问题
-
After surface refinement, we perform the volume subdivision step followed by an additional surface refinement step. (第五页)
-
pipline中MT层前一个图的位置
- 初始化阶段mlp的输入输出都作为图神经网络的输入
类别: text-3D